

I am an incoming master's student at HCP Lab, Sun Yat-sen University, advised by Prof. Guanbin Li. Previously, I received my B.Eng. in Artificial Intelligence from Xidian University, and spent a memorable three months at Westlake University, where I was fortunate to work with Prof. Yandong Wen.
My research interests lie in video generation and world models. I am especially interested in:
- Generative reasoning : understanding the internal reasoning mechanisms of video models and large language models, and exploring how such abilities may generalize.
- Physical intelligence : exploring how models can learn physical dynamics, spatial-temporal interactions, and actionable representations from real world data and simulation.
I am still exploring these fields and always happy to learn from different perspectives. Please feel free to reach out if you would like to exchange ideas, discuss research, or explore possible collaborations.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "News
Selected Publications (view all ) * Equal Contribution † Corresponding Author
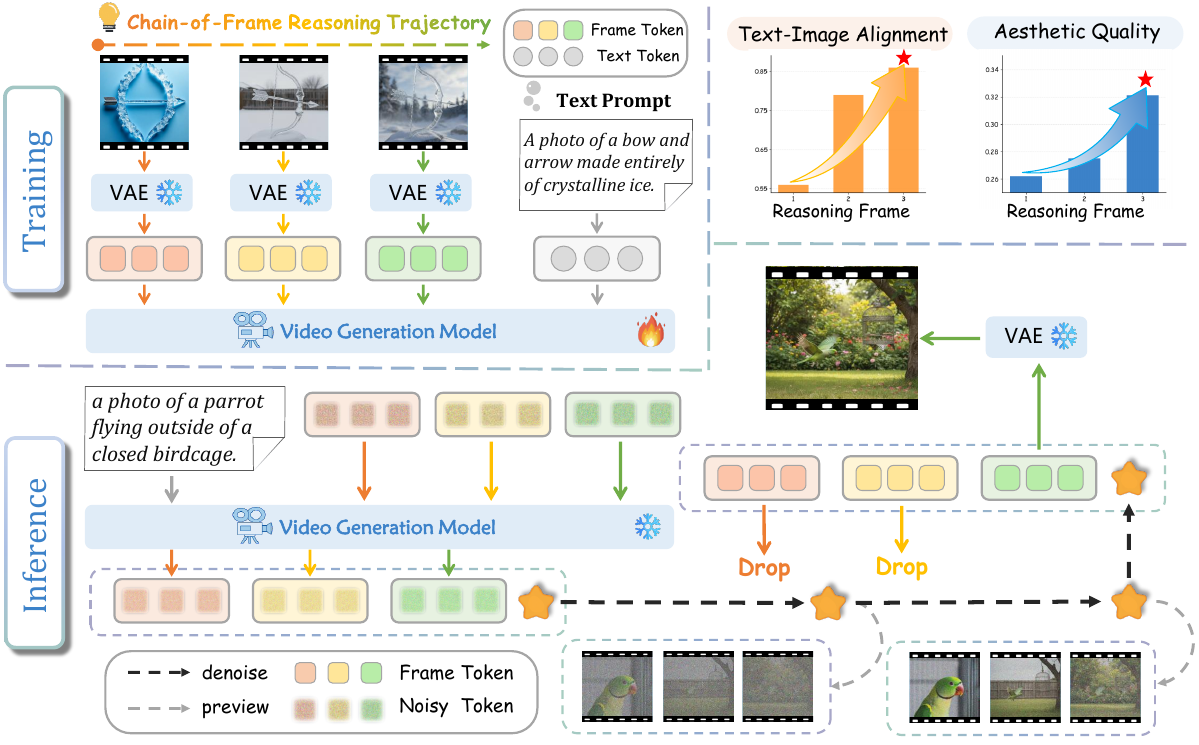
CoF-T2I: Video Models as Pure Visual Reasoners for Text-to-Image Generation
Chengzhuo Tong*, Mingkun Chang*, Shenglong Zhang, Yuran Wang, Cheng Liang, Zhizheng Zhao, Ruichuan An, Bohan Zeng, Yang Shi, Yifan Dai, Ziming Zhao, Guanbin Li, Pengfei Wan, Yuanxing Zhang, Wentao Zhang†
ICML 2026
[TL;DR] [Paper] [Project] [Code]
CoF-T2I studies how video models can perform frame-by-frame visual reasoning for text-to-image generation, using intermediate frames as explicit reasoning steps toward the final image.
CoF-T2I: Video Models as Pure Visual Reasoners for Text-to-Image Generation
Chengzhuo Tong*, Mingkun Chang*, Shenglong Zhang, Yuran Wang, Cheng Liang, Zhizheng Zhao, Ruichuan An, Bohan Zeng, Yang Shi, Yifan Dai, Ziming Zhao, Guanbin Li, Pengfei Wan, Yuanxing Zhang, Wentao Zhang†
ICML 2026
[TL;DR] [Paper] [Project] [Code]
CoF-T2I studies how video models can perform frame-by-frame visual reasoning for text-to-image generation, using intermediate frames as explicit reasoning steps toward the final image.

RealityBridge: Bridging Editable 3D Gaussian Splatting Driving Simulations and Real-World Videos
Zhenhua Wu*, Yun Pang*, Mingkun Chang*, Yuwei Ning, Liangzhi Wang, Yi Xiao, Guanbin Li†
arXiv preprint
RealityBridge is a structure-preserving and asset-aware Sim-to-Real framework for improving edited 3DGS driving videos, targeting artifact removal, realism, and temporal consistency.
RealityBridge: Bridging Editable 3D Gaussian Splatting Driving Simulations and Real-World Videos
Zhenhua Wu*, Yun Pang*, Mingkun Chang*, Yuwei Ning, Liangzhi Wang, Yi Xiao, Guanbin Li†
arXiv preprint
RealityBridge is a structure-preserving and asset-aware Sim-to-Real framework for improving edited 3DGS driving videos, targeting artifact removal, realism, and temporal consistency.
All publications
Selected Projects (view all )

OpenWorldLib
Core Contributor · 2026 · 828 stars
World Models, Multimodal Generation, Unified Inference Framework
A unified open-source codebase for advanced world models, integrating perception-centered world-model methods across visual generation, reasoning, VLA, and simulation-related tasks.
OpenWorldLib
Core Contributor · 2026 · 828 stars
World Models, Multimodal Generation, Unified Inference Framework
A unified open-source codebase for advanced world models, integrating perception-centered world-model methods across visual generation, reasoning, VLA, and simulation-related tasks.
All projects
Background
Education
M.E. Student